

The Oops! Pattern – In Sample / Out of Sample
The terms In Sample and Out of Sample refer to a technique for backtesting trading strategies (which is extensively covered in our Trading System Mentor Course) where there is some kind of optimisation or data mining taking place, i.e. finding the ideal parameters to trade with. It’s common to use two sets of data, however, I was always taught to use three. Here’s how it works…
- Take a data set, let’s use 2000 through 2015.
- Divide that set into three, so we’ll use 2000-2005, 2005-2010 and 2010-2015
- Next, take the middle set 2005-2010, which is known as the In-Sample data, and do all testing, data mining and wanted optimisation on it.
- Then take the parameters and rules from that and apply it to the other two sets of data, which are both considered the Out of Sample data.
If the results appear consistent across the entire data series then you may be on to something.
To offer up a real example of both in-sample/out of sample performance and data mining we only need look at some older trading books, the best example being Long Term Secrets to Short Term Trading by Larry Williams. This book was published in 90’s and referenced trades between September 1987 and August 1998 (our in-sample data). Therefore we now have an additional 17-years of data since the book was published which will be our out of sample data. Also, the book contains extensive data mining, which we’ll discuss shortly.
The specific pattern we’ll discuss here is the famed Oops! pattern (page 113). This is where the S&P 500 futures opens below the prior days low. If prices rally from that weak open and penetrate the low of the prior day, a long position is initiated (the opposite is true for a short setup although this example will only deal with the long side as per the book). I’ve managed to match the performance reasonably well to that shown in the book (mine is slightly better) so we’re on the right path.
But here’s the twist to the setup; any signal generated on a Wednesday or Thursday is ignored. Why? Because they were probably losing days and that’s what data mining is – purposely filtering out the bad parts of a system. Usually when data mining is done the robustness of the system is questionable, meaning that performance will usually deteriorate into the future. The fact that we now have another 17-years worth of out of sample data we’ll see if that’s the case.
Consider the following table:
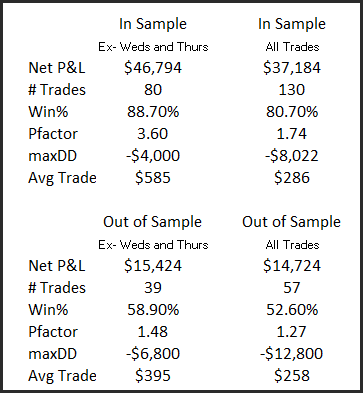
The in-sample data with the removal of Weds/Thurs trades is impressive; an 88% win rate and an average trade of $585 per contract. Even the inclusion of those two losing days the data is still reasonably good; 80% win rate with an average trade of $286. The difference in net profit between the two sets of data is 20.5% which is why Wedsnesday and Thursday are dropped.
Let’s now compare with the out of sample data. Removing the Weds/Thurs trades as per the book produces a 58.9% win rate with an average trade of $395, some 34% lower than the in-sample data. Interestingly enough taking all trades regardless remains reasonably static, specifically the average trade is $258, or just 10% lower than the in-sample. Also note that the net profitability gap has now closed to just 4.5% vs 20.5%. In other words the more robust method has held itself together a lot better than the data mined method – which is to be expected.
The following table shows the variance of daily profitability. The desired trading days listed in the in-sample data were Monday, Tuesday and Friday. Wednesday was most likely excluded because the average trade was just $63 and Thursday was excluded because it was a losing proposition. However, during the out of sample data you can see how these numbers change, specifically Thursday has now become a much better trading proposition, in fact if the book was written now the Thursday would be included and just Wednesday would be left aside. And this is the issue with data mining and optimisation; the market is constantly fluid and changing. It’s impossible to know what the best parameter will be for the coming period and by the time it’s known, it’s usually too late.

There remains a lot of issues with this strategy. Firstly, it’s a single market system with a very limited sample of trades. We’d want to test the same setup across a wide portfolio of index futures, ETFs or stocks to really understand if it actually has an edge or are we just seeing a random pattern in the data. Secondly, there’s less than 200 trades since 1987, which is about 7 trades a year. That’s a lot of waiting around and not much of a return on investment. The extension of that is that one is then inclined to go data mining for a lot more patterns (which is exactly what Williams has done in the book) to take up the slack which in turn exacerbates the issues outlined above.


